Amazon has millions of customers who offer their products on its website by individually contacting buyers; third-party sales are about 60% of all sales. It also comes with what is known as ‘Fulfilled by Amazon’ (FBA), whereby the company takes full responsibility for the delivery of products sold by the sellers. From February 2024, FBA fees will be adjusted based on inventory size, meaning sellers with larger stockrooms will pay more to use Amazon’s cheaper but more expensive, optimal storage centers.
- In 2023, over 12 billion worldwide consumers shopped through Amazon.
- Amazon's global sales reached almost $575 billion in 2023.
- About 87% of the total revenues are derived from the gross merchandise value sales of various products through the stores, while the remaining is from third-party sellers, subscriptions, and AWS.
- Amazon reported its 2024 second-quarter earnings on Thursday, August 1.
- Amazon reported its 2024 second-quarter earnings on Thursday, August 1.
- In 2024, earnings per share (EPS) were $1.26, $0.23 higher than analysts expected.
- In 2024, the company’s revenue for the quarter was $147.98 billion, slightly below the expected $148.68 billion.
- European regulators prevented an attempt to buy iRobot, a vacuum cleaner manufacturer, in January 2024 due to Amazon’s market dominance.
What is Amazon Review & Ratings Data Scraping?
Amazon review scraping is gathering customer reviews of products listed on the Amazon website and other related applications and platforms. This may involve crawling through the Amazon website via automated software tools or scripts, finding relevant review data, and then downloading it. The extracted data usually consists of the text of the review, the star rating made by the reviewer, and some details about the reviewer, Occasionally, other meta-information, such as the date the review was published or whether the reviewer was a verified purchaser, may be included. It can be applied in various applications like analyzing sentiments, customer feedback on the product under consideration, the market, and competition analysis.
However, scraping Amazon review data has ethical and legal issues. Amazon does not allow any form of web scraping without permission because it harms the company. It can also be deemed a form of hacking into the company’s website and infringing on the users’ privacy.
Thus, scraped data may not generalize overall customer opinions since specific reviews can be fake or biased. Those needing such data are advised to utilize the official API offered by Amazon, which permits legal access to the review data, or use the API provided by the third parties granted permission.
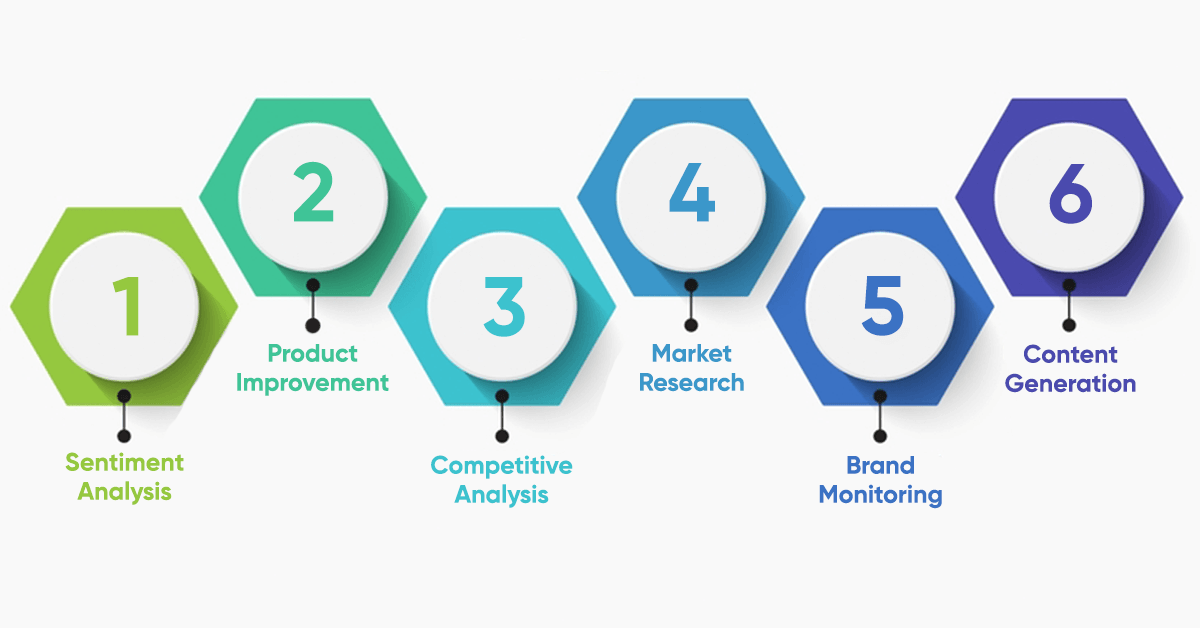
Why Scrape Amazon Product Reviews?
Amazon has become one of the most prominent leaders in the e-commerce segment worldwide, focusing on its customers, challenging itself, and learning from its errors. Consequently, it would be ideal for your organization to focus on your primary business operations and outsource the collection of Amazon data to a specialized data scraping company. They can handle the data scraping according to your schedule, allowing you to concentrate on what you do best.
Sentiment Analysis
The logic behind this is that by gauging the language used in the comments that various companies receive, firms can derive the levels of satisfaction of clients. Sentiment analysis can show whether customers are mostly happy, dissatisfied, or neutral toward a product. Such awareness helps businesses advance their advertising techniques, enhance organizational customer relations, and analyze data regarding product and service production.
Product Improvement
Opinions can be more informative than factual information; often, they include precise descriptions of the features, quality, and utility of a particular product. Through web scraping and subsequent data analysis of this information, firms can easily find various sectors that require enhancement or define features that customers like. This can help restrain the development of subsequent products or modifications to currently available ones that intend to improve the fulfillment of their purpose by the customers.
Competitive Analysis
Collecting reviews of products offered by competitors enables acquiring insight into the competitor’s strategies. In short, knowledge of the specific details of what the customer feels is positive or negative about a competitor's suit can give practical intelligence in areas lacking or where a company places the chance to generate a competitive edge.
Market Research
or services. Extracting large amounts of reviews can provide insights such as a gradual shift in customer preference toward features or a change to new expectations. This proves to be very useful for determining trends in product development, marketing strategies, and business approaches.
Brand Monitoring
Amazon has enabled corporations to understand how people perceive brands regarding many products sold by the companies. Before negative images are created and widely spread, the company can address them before they worsen. It may be a mode or a manufacturing defect, flawed marketing, or dissatisfaction with customer service.
Content Generation
This means that positive reviews are valuable in and of themselves, and potential customers can also be a great source of factual material for your advertising copy. Hence, by troubling the appropriate reviews and then picking the best ones, a business can create appealing testimonials, case studies, or perhaps social media posts that will attract possible customers.
Steps to Scrape Amazon Product Reviews and Ratings
This tutorial requires Installing Python 3.8 or later and the following three packages: Requests, Pandas, Beautiful Soup, and lxml.
After that, make a header and import all required libraries.
import requests
from bs4 import BeautifulSoup
import pandas as pd
custom_headers = {
"accept-language": "en-GB,en;q=0.9",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15",
}
Implementing custom headers is crucial to stay active when gathering Amazon reviews.
Obtaining the Review Items
Get every review object and extract the required data when ready to start scraping. Finding a CSS selector and using the.select function will this selection to locate the reviews on Amazon:
div.review
The following code can be used to collect them:
review_elements = soup.select("div.review")
Next, a selection of reviews will be available to peruse and extract the relevant information from.
You will need a for loop and an array to which you can add the processed reviews to start iterating:
scraped_reviews = [] for review in review_elements:
Review Rating
The item to be retrieved after this is the review rating. You can try the following CSS to locate it:
i.review-rating
Let's remove the unnecessary text that is there in the rating string:
r_rating_element = review.select_one("i.review-rating")
r_rating = r_rating_element.text.replace("out of 5 stars", "") if r_rating_element else None
How to Extract Headlines of the Reviews
To get the title of the review, use this selection:
a.review-title
As shown below, the actual title text is as follows.
r_title_element = review.select_one("a.review-title")
r_title_span_element = r_title_element.select_one("span:not([class])") if r_title_element else None
r_title = r_title_span_element.text if r_title_span_element else None
Examine the document
To find the review text itself, choose the following selection:
span.review-text
After that, you can take relevant content out of Amazon reviews:
r_content_element = review.select_one("span.review-text")
r_content = r_content_element.text if r_content_element else None
How to Extract Date of the Reviews
It's also necessary to extract the date from the review. You can find it by using the CSS selector that follows:
span.review-date
The following code can be used to extract the date value from the object:
r_date_element = review.select_one("span.review-date")
r_date = r_date_element.text if r_date_element else None
Confirmation
Additionally, you can verify if the review has been validated or not. You can make this selection to get the object that has this data in it:
span.a-size-mini
And extracted using the following code:
r_verified_element = review.select_one("span.a-size-mini")
r_verified = r_verified_element.text if r_verified_element else None
How to Extract Product Review Images
Ultimately, you can use this option to get the URLs of any recently uploaded pictures to the review:
img.review-image-tile
After that, extract them using the code below:
r_image_element = review.select_one("img.review-image-tile")
r_image = r_image_element.attrs["src"] if r_image_element else None
After obtaining all of this information, merge it into a single object. Next, before starting our for loop, add that item to the set of product reviews you have created:
r = {
"author": r_author,
"rating": r_rating,
"title": r_title,
"content": r_content,
"date": r_date,
"verified": r_verified,
"image_url": r_image
}
scraped_reviews.append(r)
Exporting data
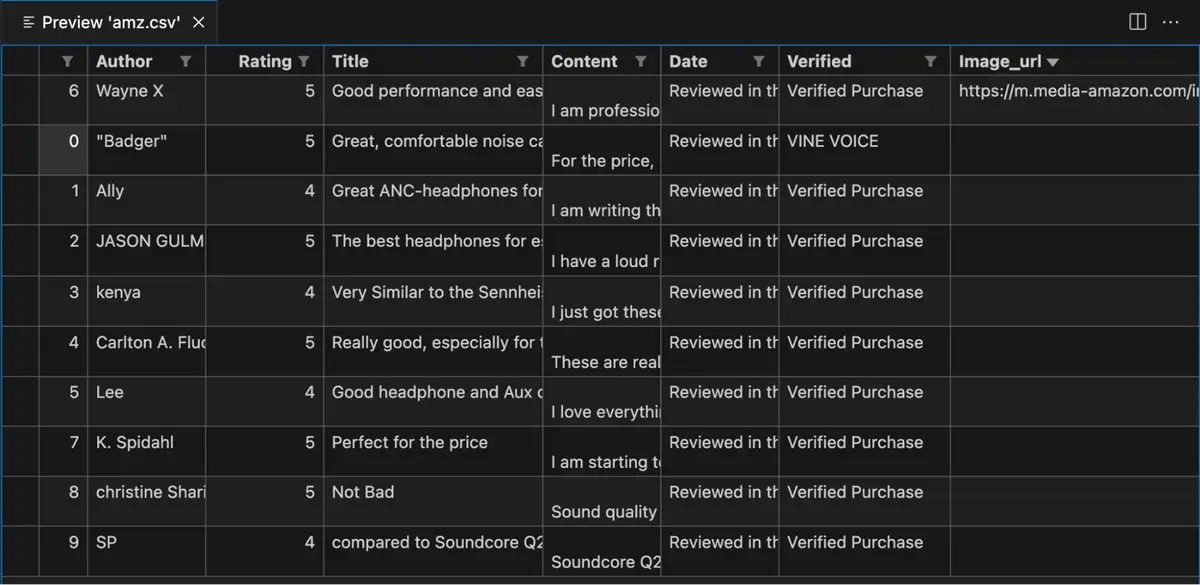
After all the data has been scraped, the last step is to export the data to a file. The CSV format of the data may be exported using the code provided:
search_url = "https://www.amazon.com/BERIBES-Cancelling-Transparent-Soft-Earpads-Charging-Black/product-reviews/B0CDC4X65Q/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews"
soup = get_soup(search_url)
reviews = get_reviews(soup)
df = pd.DataFrame(data=reviews)
df.to_csv("amz.csv")
After the script runs, your data is in the file amz.csv:
The complete script is as follows:
import requests
from bs4 import BeautifulSoup
import pandas as pd
custom_headers = {
"Accept-language": "en-GB,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"User-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15",
}
def get_soup(url):
response = requests.get(url, headers=custom_headers)
if response.status_code != 200:
print("Error in getting webpage")
exit(-1)
soup = BeautifulSoup(response.text, "lxml")
return soup
def get_reviews(soup):
review_elements = soup.select("div.review")
scraped_reviews = []
for review in review_elements:
r_author_element = review.select_one("span.a-profile-name")
r_author = r_author_element.text if r_author_element else None
r_rating_element = review.select_one("i.review-rating")
r_rating = r_rating_element.text.replace("out of 5 stars", "") if r_rating_element else None
r_title_element = review.select_one("a.review-title")
r_title_span_element = r_title_element.select_one("span:not([class])") if r_title_element else None
r_title = r_title_span_element.text if r_title_span_element else None
r_content_element = review.select_one("span.review-text")
r_content = r_content_element.text if r_content_element else None
r_date_element = review.select_one("span.review-date")
r_date = r_date_element.text if r_date_element else None
r_verified_element = review.select_one("span.a-size-mini")
r_verified = r_verified_element.text if r_verified_element else None
r_image_element = review.select_one("img.review-image-tile")
r_image = r_image_element.attrs["src"] if r_image_element else None
r = {
"author": r_author,
"rating": r_rating,
"title": r_title,
"content": r_content,
"date": r_date,
"verified": r_verified,
"image_url": r_image
}
scraped_reviews.append(r)
return scraped_reviews
def main():
search_url = "https://www.amazon.com/BERIBES-Cancelling-Transparent-Soft-Earpads-Charging-Black/product-reviews/B0CDC4X65Q/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews"
soup = get_soup(search_url)
data = get_reviews(soup)
df = pd.DataFrame(data=data)
df.to_csv("amz.csv")
if __name__ == '__main__':
main()
Challenges Faced While Scraping Amazon Review Data:

Amazon.com is the biggest online store in the world and the first point of call for many consumers when looking for goods. There is a need for e-commerce sellers to analyze this data well and enhance their products to convert this group of shoppers to loyal consumers.
Data Inconsistencies
Amazon's website structure and review formatting may change over time, causing scripts that worked previously to break. These changes require continuous monitoring and updating of scraping tools to ensure accurate and consistent data extraction.
Legal and Ethical Issues
Amazon has basic policies regarding scraping on its site. If you scrape their site, you will likely find yourself on the wrong end of the law or have your account blocked. There is also the ethical issue: scraping may impact people’s rights for policy if you do not carefully choose what data to collect.
Blocking by Amazon
Amazon has measures that prevent bots from crawling its site. It may limit or completely ban your IP address or require you to prove you’re a human through a CAPTCHA. For this, you have to develop strategies such as frequently changing your IP address, which can also be somewhat cumbersome.
Changes in Website Design
Amazon may decide to redesign its website, which means you might need to scrape the wrong structure. For instance, if the case decided to make the reviews less conspicuous, your tool could not locate those reviews again.
Duplicate and Fake Reviews
It supports the opinion that not all reviews are genuine. If your tool gathers these reviews, it could skew the results you get. You must seek ways to eliminate duplicate results to get the correct result.
Rate Limiting
They also set quotas, limiting the number of calls you can make to their site in a given time period. Like other online platforms, they might block you if you make many requests at close intervals. It becomes complicated to amass large quantities of data in relatively little time here.
Data Privacy and Security
It is important to remember that if you scrape a lot of data, some might compromise nature, and it has to be adequately secured. It can be stolen or misused if improperly safeguarded, resulting in significant issues.
Conclusion
From a business perspective, scraping Amazon reviews is highly beneficial because it can give the owner information about natural, organic consumer experiences, ratings, and trends. Such information enables companies to make the right choices concerning which products to sell, the level of customer satisfaction, and dealing with competition. By using professional services like Scraping Intelligence, businesses can safely and effectively scrape Amazon reviews without risking legal issues. These services ensure data quality by filtering out fake reviews and adapting to Amazon’s website structure changes. While scraping Amazon data, we can obtain vast data to help us make crucial decisions. However, hiring professional scraping services is best to avoid problems like frequent queries or predictable behavior leading to being blocked. These services are experienced in handling legal restrictions and ensuring reliable data collection.
Headquarter
10685-B Hazelhurst Dr.#23604 Houston,TX 77043 USA
Incredible Solutions After Consultation
- → Industry Specific Expert Opinion
- → Assistance in Data-Driven Decision Making
- → Insights Through Data Analysis